文件传输系列:rsync
SCP 的另一个绝佳替选
什么是 rsync
rsync (remote synchronize) 是一款实现远程同步功能的软件,它在同步文件的同时,可以保持原来文件的权限、时间、软硬链接等附加信息。
rsync 是类 Unix 系统下的数据镜像备份工具。它能同步更新两处计算机的文件与目录,并适当利用差分编码以减少数据传输量。 rsync 中的一项同类软件不常见的重要特性是每个目标的镜像只需发送一次。rsync 可以拷贝/显示目录内容,以及拷贝文件,并可选压缩以及递归拷贝。
rsync 默认监听 TCP 端口 873,以原生 rsync 传输协议或者透过远程 shell 如 RSH 或者 SSH 提供文件。SSH 模式下,rsync 客户端运行程序必须同时在本地和远程机器上安装。
rsync 算法
rsync 的算法如下:(假设源文件名为 fileSrc,目的文件叫 fileDst)
分块 Checksum 算法
首先,我们会把 fileDst 的文件平均切分成若干个小块,比如每块 512 个字节,然后对每块计算两个 checksum,一个叫 rolling checksum,是弱 checksum,32 位的 checksum,其使用的是 Mark Adler 发明的 adler-32 算法,另一个是强 checksum,128 位的,以前用 md4,现在用 md5。为什么要这样?因为若干年前的硬件上跑 md4 的算法太慢了,所以,需要一个快算法来鉴别文件块的不同,但是弱的 adler-32 算法碰撞概率太高了,所以我们还要引入强的 checksum 算法以保证两文件块是相同的。也就是说,弱的 checksum 是用来区别不同,而强的是用来确认相同。
传输算法
同步目标端会把 fileDst 的一个 checksum 列表传给同步源,这个列表里包括了三个东西,rolling checksum (32bits),md5 checksume (128bits),文件块编号。同步源机器拿到了这个列表后,会对 fileSrc 做同样的 checksum,然后和 fileDst 的 checksum 做对比,这样就知道哪些文件块改变了。
但是
如果我 fileSrc 这边在文件中间加了一个字符,这样后面的文件块都会位移一个字符,这样就完全和 fileDst 这边的不一样了,但理论上来说,我应该只需要传一个字符就好了。这个怎么解决?
如果这个 checksum 列表特别长,而两边相同的文件块可能并不是一样的顺序,那就需要查找,线性的查找起来应该特别慢吧。这个怎么解决?
Checksum 查找算法
同步源端拿到 fileDst 的 checksum 数组后,会把这个数据存到一个 hash table 中,用 rolling checksum 做 hash,以便获得 O(1) 时间复杂度的查找性能。这个 hash table 是 16 bits 的,所以,hash table 的尺寸是 2 的 16 次方,对 rolling checksum 的 hash 会被散列到 0 到 $ 2^{16} – 1 $ 中的某个整数值。
比对算法
-
取
fileSrc的第一个文件块(我们假设的是 512 个长度),也就是从fileSrc的第 1 个字节到第 512 个字节,取出来后做rolling checksum计算。计算好的值到hash表中查询。 -
如果查到了,说明发现在
fileDst中有潜在相同的文件块,于是就再比较 · 的checksum,因为rolling checksume太弱了,可能发生碰撞。于是还要算md5的 128 bits 的checksum,这样一来,我们就有 $2^{-(32+128)} = 2^{-160} $ 的概率发生碰撞,这小到可以忽略。如果rolling checksum和md5 checksum都相同,那就可以说明在fileDst中有相同的块,记下这一块在fileDst下的文件编号。 -
如果
fileSrc的rolling checksum没有在hash table中找到,那就不用算md5 checksum了。表示这一块中有不同的信息。总之,只要rolling checksum或md5 checksum其中有一个在fileDst的checksum hash表中找不到匹配项,那么就会触发算法对fileSrc的 rolling 动作。于是,算法会住后 step 1 个字节,取fileSrc中字节 2-513 的文件块要做checksum,然后继续第一步 – 这就是为什么叫rolling checksum。 -
这样,我们就可以找出
fileSrc相邻两次匹配中的那些文本字符,这些就是我们要往同步目标端传的文件内容了。
Rolling Checksum 算法
rolling checksum 算法也叫 Rabin-Karp 算法,由 Richard M. Karp 和 Michael O. Rabin 在 1987 年发表,它用来解决多模式串匹配问题。其最大的精髓是,当往后面 step 1 个字符的时候,不用全部重新计算所有的 checksum,也就是说,从 [0, 512] rolling 到 [1, 513] 时,不需要重新计算从 1 到 513 的 checksum,而是重用 [0,512] 的 checksum 直接算出来。
其公式可以表示为:
hash ( t[0, m-1] ) = t[0] * b^(m-1) + t[1] * b^[m-2] ..... t[m-1] * b^0其中的 b 是一个常数基数,在 Rabin-Karp 算法中,一般取值为 256。
于是,在计算 hash ( t[1, m] ) 时,只需要下面这样就可以了:
hash( t[1, m] ) = hash ( t[0, m-1] ) - t[0] * b^(m-1) + t[m] * b ^0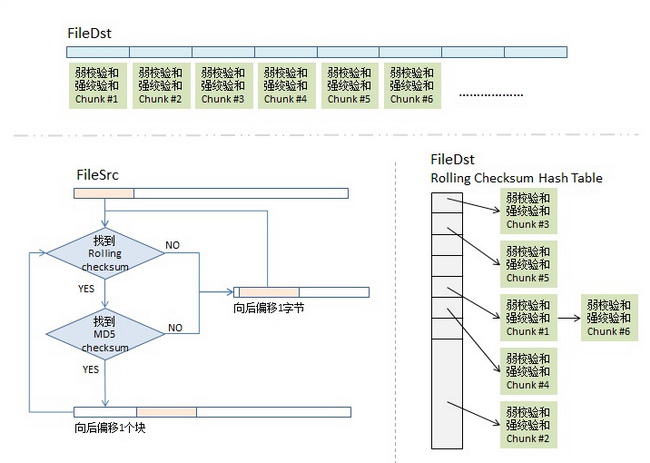
最终,得到的数据组可以想象为 BT 协议下载 torrent :一些文件块已下载(匹配上),其他的文件块还未下载(未匹配上)。然后,同步端将这些未匹配上的文件打上标号发送,目的端根据标号重组文件就完成了同步。
使用 rsync
rsync [OPTION]... SRC DEST
rsync [OPTION]... SRC [USER@] host:DEST
rsync [OPTION]... [USER@] HOST:SRC DEST
rsync [OPTION]... [USER@] HOST::SRC DEST
rsync [OPTION]... SRC [USER@] HOST::DEST
rsync [OPTION]... rsync://[USER@] HOST [:PORT]/SRC [DEST]对应于以上六种命令格式,rsync 有六种不同的工作模式:
-
拷贝本地文件。当
SRC和DES路径信息都不包含有单个冒号 “:” 分隔符时就启动这种工作模式。如:rsync -a /data/backup -
使用一个远程
shell程序 (如 rsh、ssh) 来实现将本地机器的内容拷贝到远程机器。当DST路径地址包含单个冒号 “:” 分隔符时启动该模式。如:rsync -avz *.c foo:src -
使用一个远程
shell程序 (如rsh、ssh) 来实现将远程机器的内容拷贝到本地机器。当SRC地址路径包含单个冒号 “:” 分隔符时启动该模式。如:rsync -avz foo:src/bar/data -
从远程
rsync服务器中拷贝文件到本地机。当SRC路径信息包含 “::” 分隔符时启动该模式。如:rsync -av root@192.168.78.192::www /databack -
从本地机器拷贝文件到远程
rsync服务器中。当DST路径信息包含 “::” 分隔符时启动该模式。如:rsync -av /databack root@192.168.78.192::www -
列出远程主机的文件列表。这类似于
rsync传输,不过只要在命令中省略掉本地机信息即可。如:rsync -v rsync://192.168.78.192/www
可用选项如下:
-v, --verbose 详细模式输出。
-q, --quiet 精简输出模式。
-C, --cvs-exclude 使用和 CVS 一样的方法自动忽略文件,用来排除那些不希望传输的文件。
-c, --checksum 打开校验开关,强制对文件传输进行校验。
-a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性,等于 - rlptgoD。
-r, --recursive 对子目录以递归模式处理。
-R, --relative 使用相对路径信息。
-b, --backup 创建备份,也就是对于目的已经存在有同样的文件名时,将老的文件重新命名为~filename。可以使用 --suffix 选项来指定不同的备份文件前缀。
-u, --update 仅仅进行更新,也就是跳过所有已经存在于 DST,并且文件时间晚于要备份的文件,不覆盖更新的文件。
-l, --links 保留软链结。
-L, --copy-links 想对待常规文件一样处理软链结。
-H, --hard-links 保留硬链结。
-I, --ignore-times 不跳过那些有同样的时间和长度的文件。
-p, --perms 保持文件权限。
-o, --owner 保持文件属主信息。
-g, --group 保持文件属组信息。
-D, --devices 保持设备文件信息。
-t, --times 保持文件时间信息。
-S, --sparse 对稀疏文件进行特殊处理以节省 DST 的空间。
-T --temp-dir=DIR 在 DIR 中创建临时文件。
-n, --dry-run 现实哪些文件将被传输。
-w, --whole-file 拷贝文件,不进行增量检测。
-x, --one-file-system 不要跨越文件系统边界。
-B, --block-size=SIZE 检验算法使用的块尺寸,默认是 700 字节。
-e, --rsh=command 指定使用 rsh、ssh 方式进行数据同步。
-P 等同于 --partial。
-z, --compress 对备份的文件在传输时进行压缩处理。
-h, --help 显示帮助信息。
--backup-dir 将备份文件 (如~filename) 存放在在目录下。
-suffix=SUFFIX 定义备份文件前缀。
--copy-unsafe-links 仅仅拷贝指向 SRC 路径目录树以外的链结。
--safe-links 忽略指向 SRC 路径目录树以外的链结。
--rsync-path=PATH 指定远程服务器上的 rsync 命令所在路径信息。
--existing 仅仅更新那些已经存在于 DST 的文件,而不备份那些新创建的文件。
--delete 删除那些 DST 中 SRC 没有的文件。
--delete-excluded 同样删除接收端那些被该选项指定排除的文件。
--delete-after 传输结束以后再删除。
--ignore-errors 及时出现 IO 错误也进行删除。
--max-delete=NUM 最多删除 NUM 个文件。
--partial 保留那些因故没有完全传输的文件,以是加快随后的再次传输。
--force 强制删除目录,即使不为空。
--numeric-ids 不将数字的用户和组 id 匹配为用户名和组名。
--timeout=time ip 超时时间,单位为秒。
--size-only 当决定是否要备份文件时,仅仅察看文件大小而不考虑文件时间。
--modify-window=NUM 决定文件是否时间相同时使用的时间戳窗口,默认为 0。
--compare-dest=DIR 同样比较 DIR 中的文件来决定是否需要备份。
--progress 显示备份过程。
--exclude=PATTERN 指定排除不需要传输的文件模式。
--include=PATTERN 指定不排除而需要传输的文件模式。
--exclude-from=FILE 排除 FILE 中指定模式的文件。
--include-from=FILE 不排除 FILE 指定模式匹配的文件。
--version 打印版本信息。
--address 绑定到特定的地址。
--config=FILE 指定其他的配置文件,不使用默认的 rsyncd.conf 文件。
--port=PORT 指定其他的 rsync 服务端口。
--blocking-io 对远程 shell 使用阻塞 IO。
-stats 给出某些文件的传输状态。
--progress 在传输时现实传输过程。
--log-format=formAT 指定日志文件格式。
--password-file=FILE 从 FILE 中得到密码。
--bwlimit=KBPS 限制 I/O 带宽,KBytes per second。参考
-
[2] RSYNC 的核心算法
-
[3] rsync wikipedia
-
[4] rsync command